It’s happening. The world’s falling apart. Global outages. Data centres impacted.
You’ve done the prep but if your VMs go down, none of it matters.
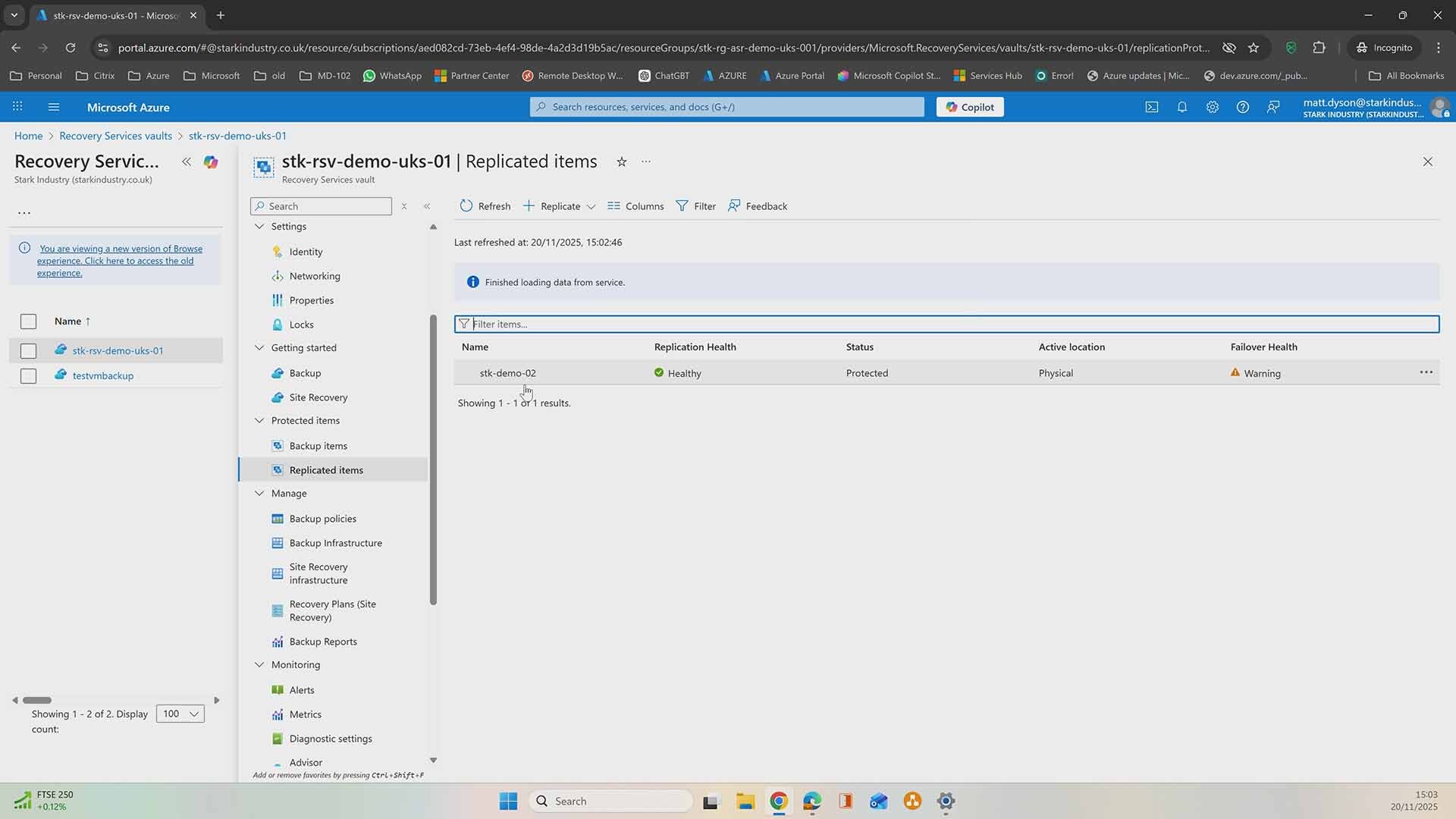
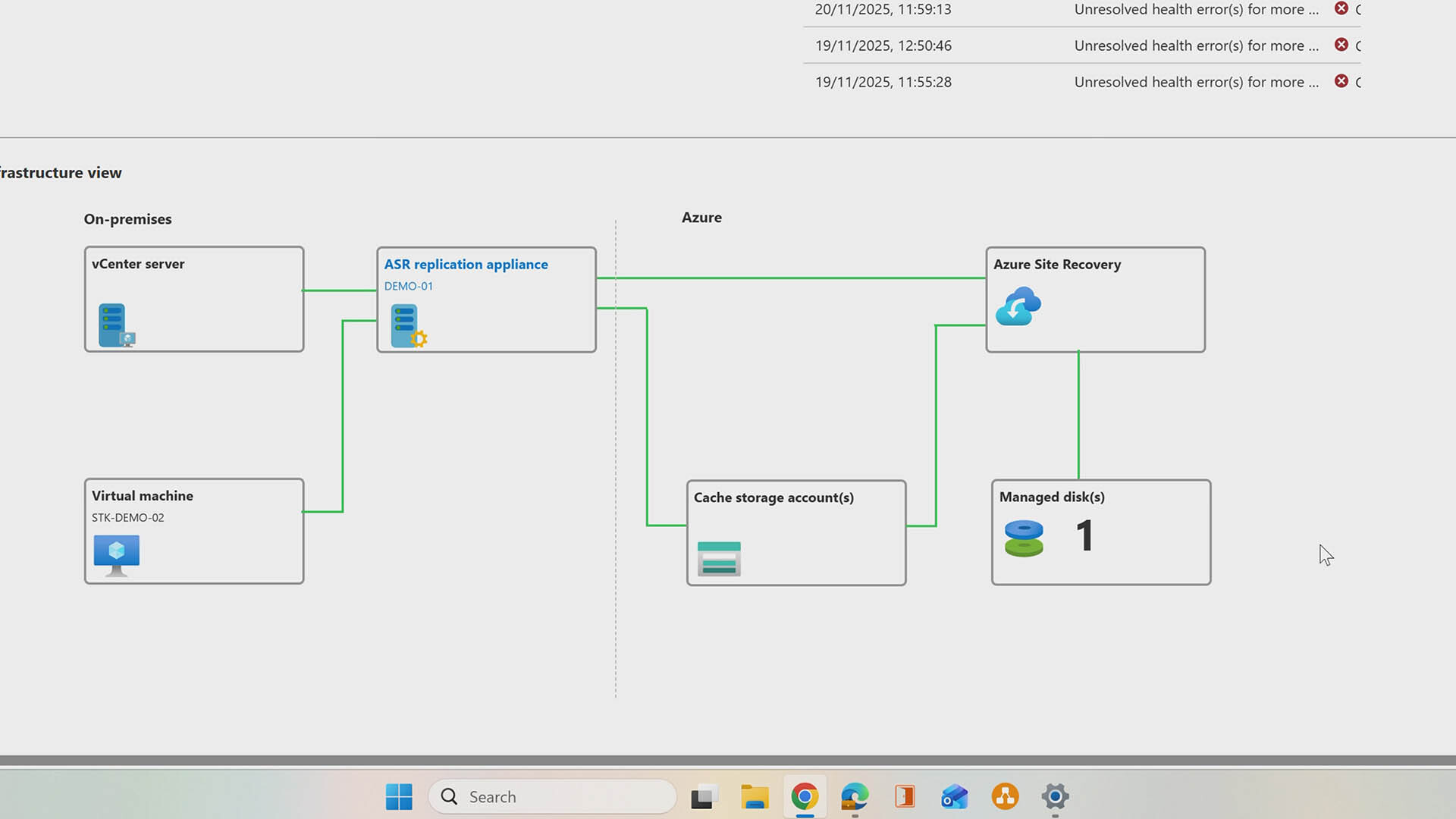
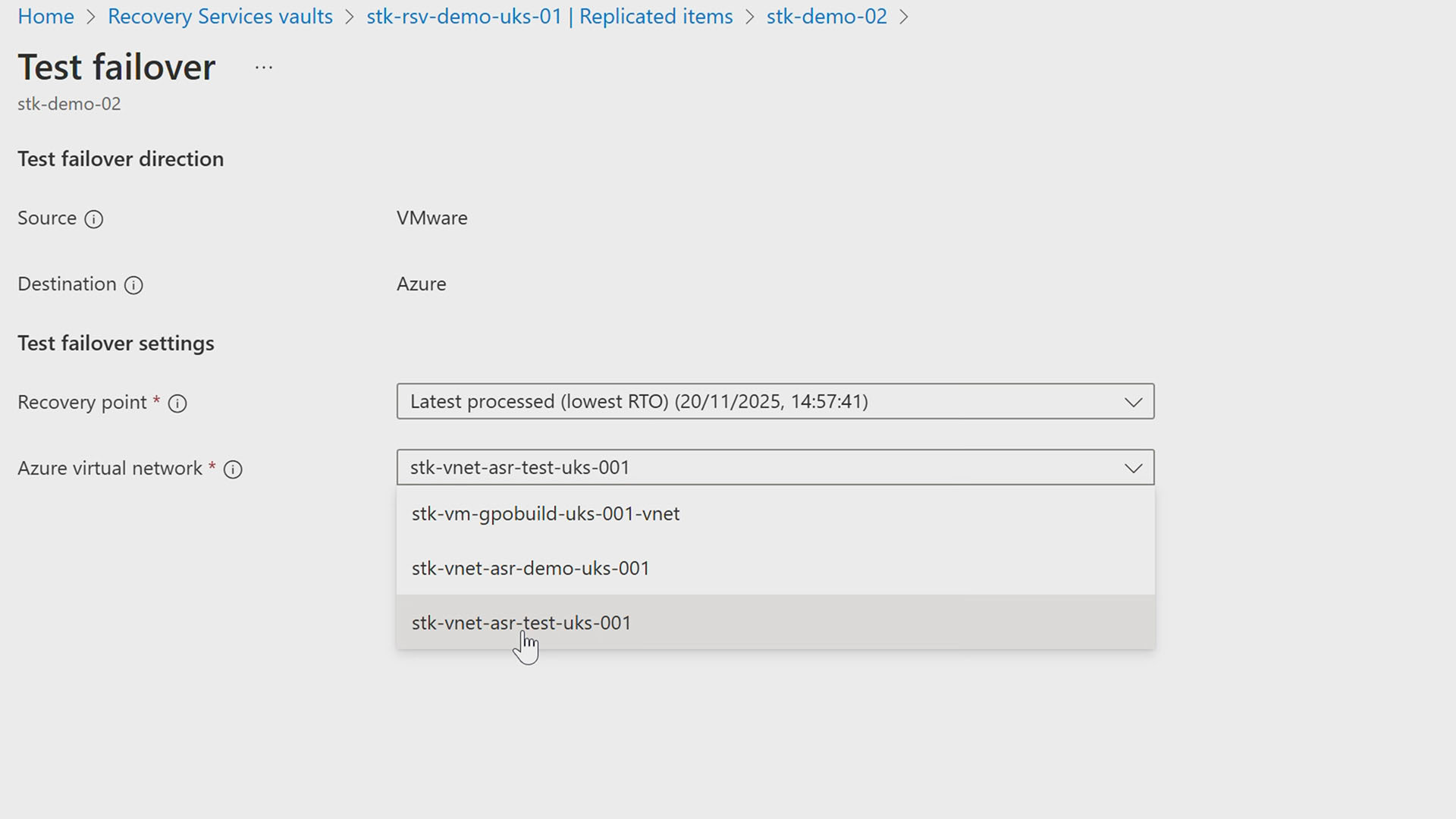
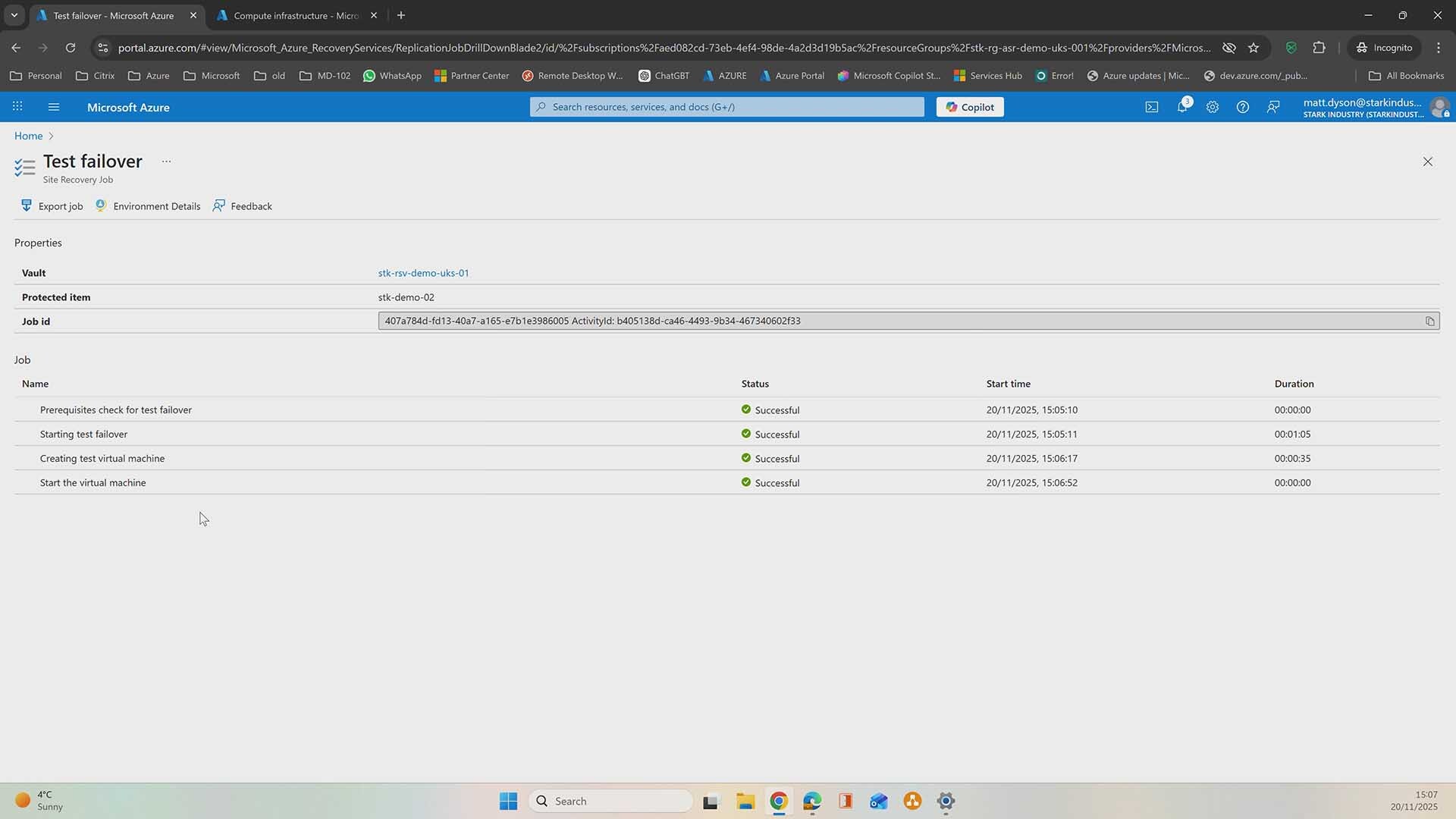
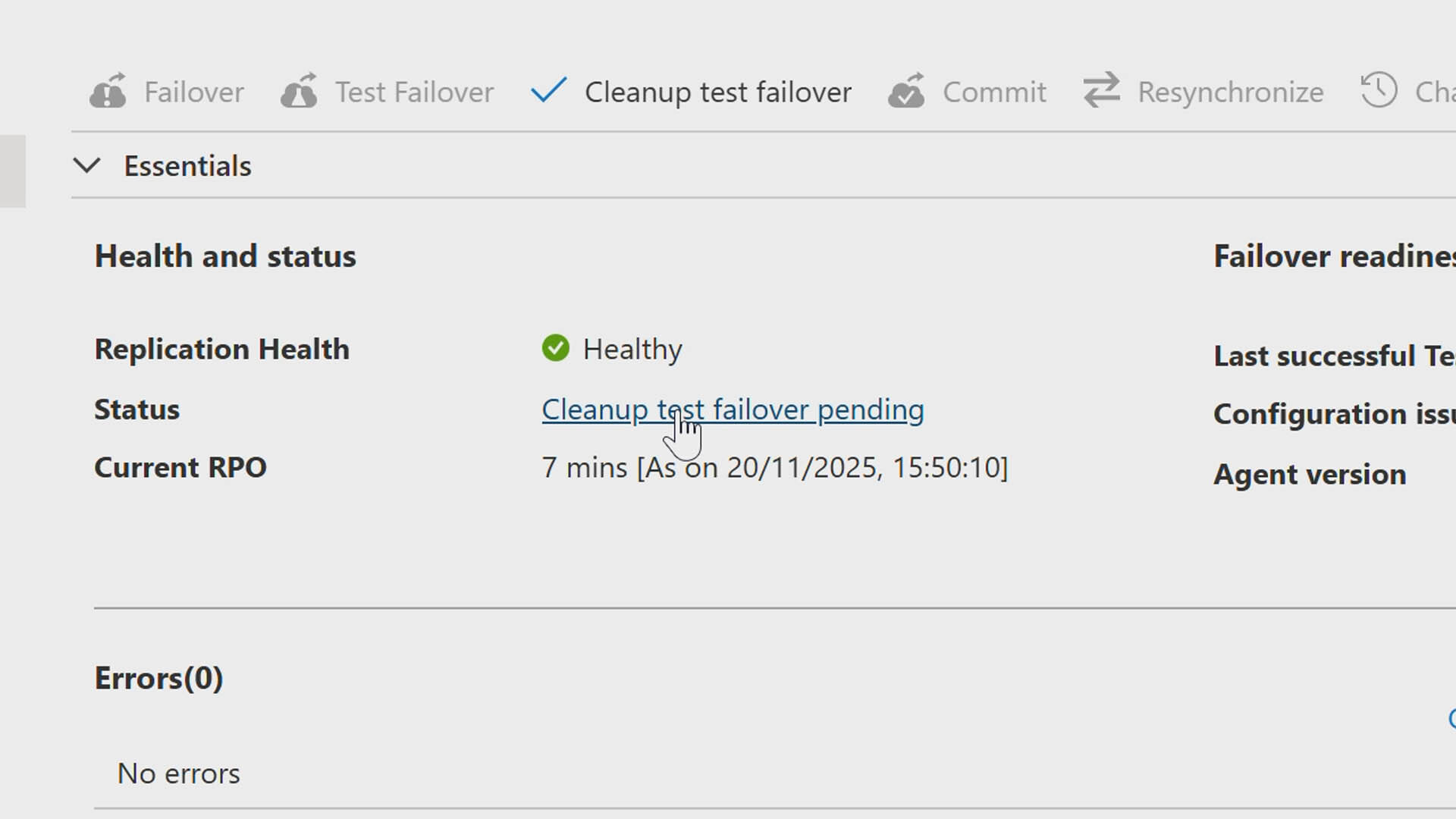
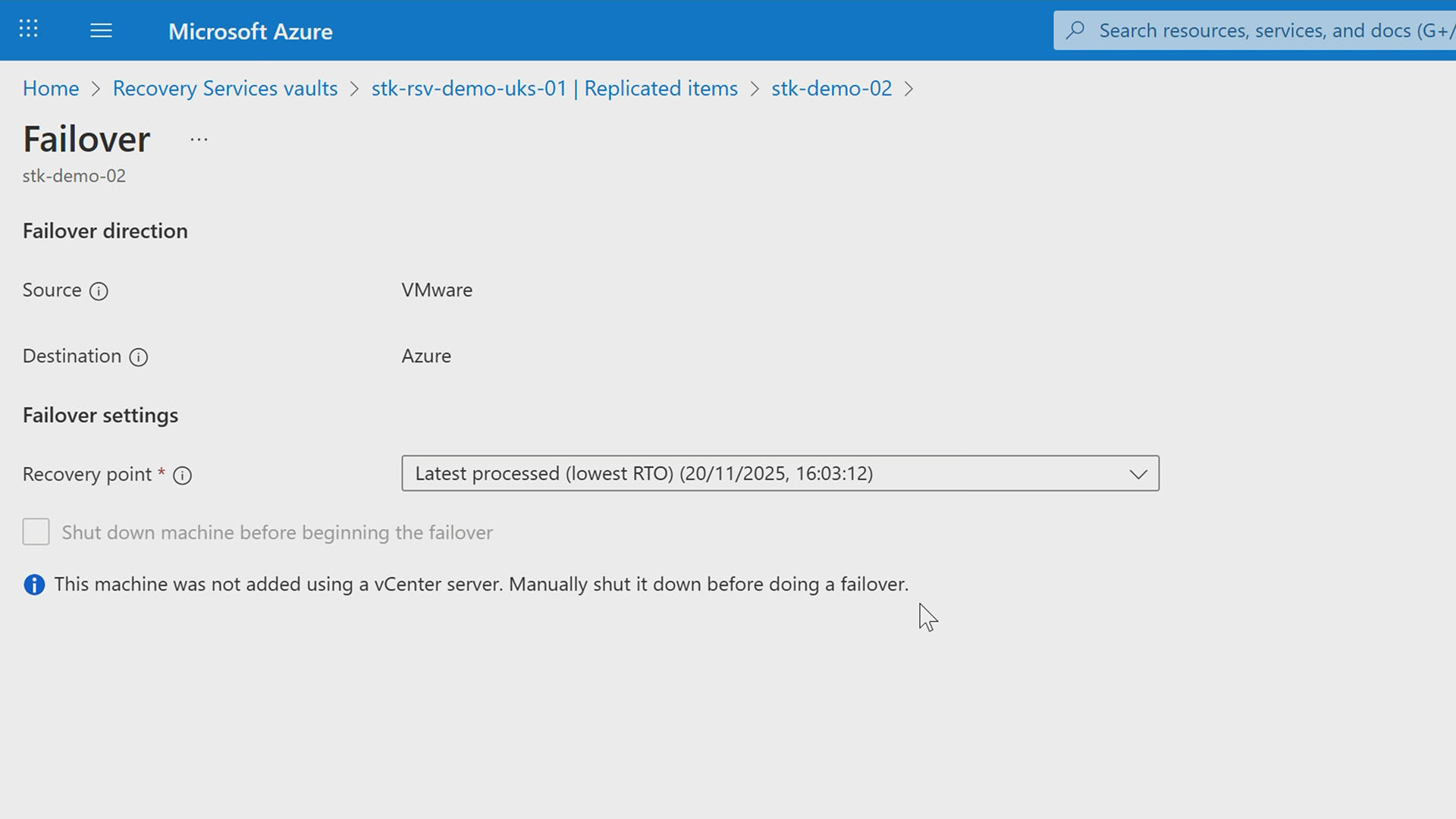
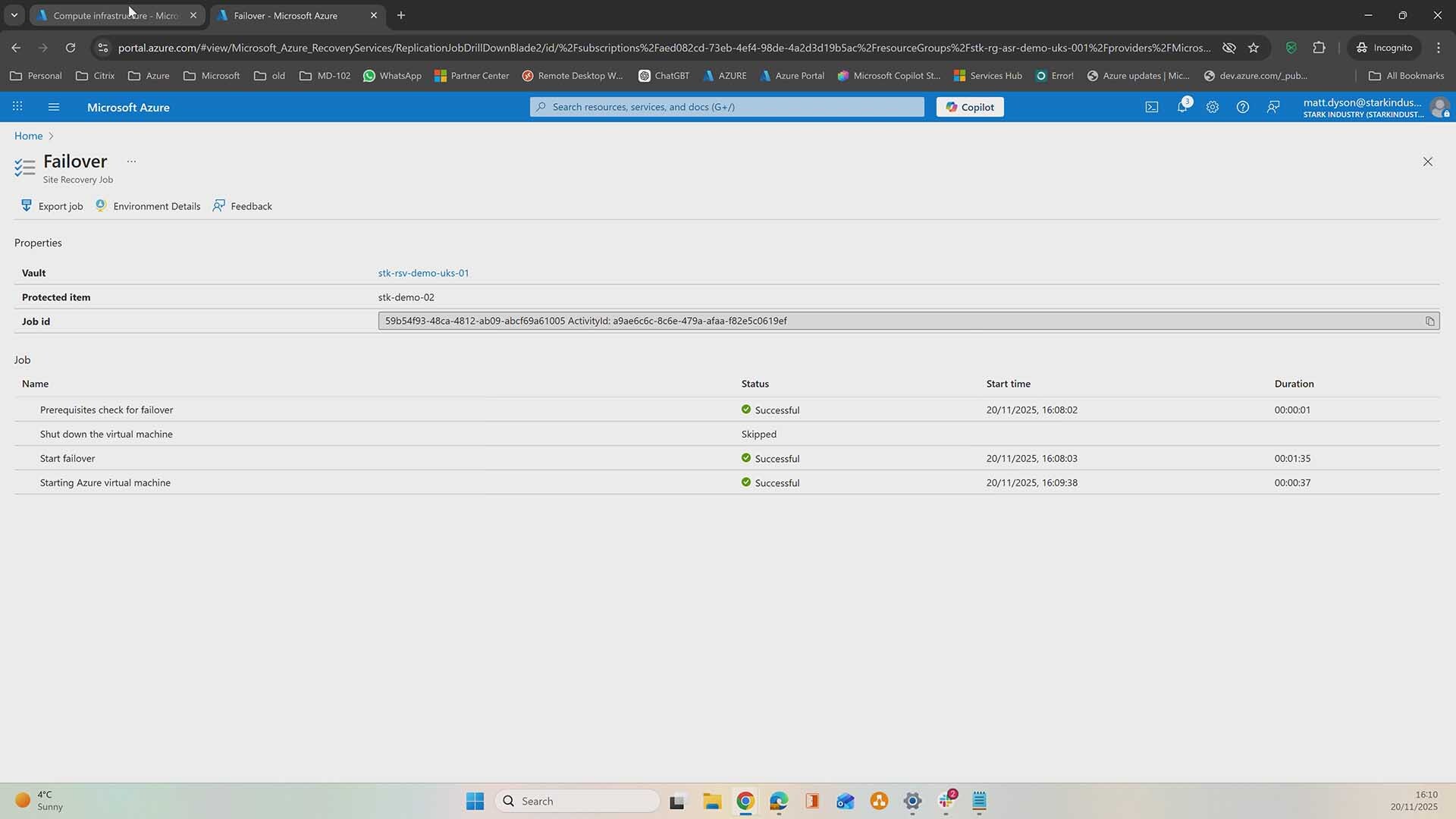
This is part two of our Azure Site Recovery series, where we move beyond configuration and into the moment that really counts: failover. If you missed part one on setting up Azure Site Recovery, it’s worth watching first.
If you want to see a failover in action, check out the demo video below to see a Azure Site Recovery failover do its thing in real time. Prefer to take it step by step? Keep reading for a clear walkthrough you can follow at your own pace.