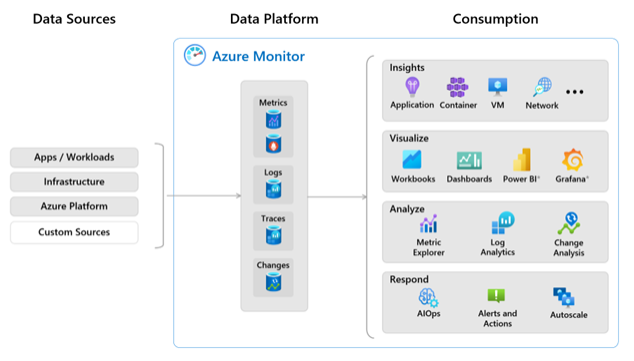
Azure Monitor offers several types of alerts, each designed for specific monitoring scenarios. Understanding which to use and when is key to effective monitoring:
1) Metric alerts for real-time monitoring
These are your first line of defence – quick, responsive, and straightforward. Metric alerts watch numerical values and trigger when they cross thresholds you define.
Picture this: It’s 3 AM and your e-commerce site’s response time suddenly spikes to 5 seconds. A metric alert can notify your on-call engineer within minutes, potentially before customers start abandoning their shopping carts. That’s the power of near real-time monitoring.
Metric alerts excel at watching vital signs like CPU usage, available memory, or request rates. You can set them to trigger immediately or to confirm a problem exists for a certain duration before alerting (nobody wants to be woken up for a 5-second CPU spike that resolves itself).
The beauty of metric alerts is their simplicity. You’re essentially saying, “Let me know when X exceeds Y for Z amount of time,” making them perfect for clear-cut monitoring scenarios.
2) Log alerts for complex pattern detection
Sometimes the issues you’re monitoring for aren’t as simple as a number crossing a threshold. That’s where log alerts come in.
Imagine you need to know when specific error patterns appear across multiple systems, or when certain users perform sensitive actions. Or maybe when a combination of factors indicates a potential problem brewing. Log alerts let you write custom queries using Kusto Query Language (KQL) to look for these complex patterns.
Consider this. A financial services company might create a log alert that triggers when:
- A user accesses customer financial data
- Outside of normal business hours
- From an IP address not previously associated with that user
- And then downloads an unusually large amount of data
No single metric could catch this potential data theft scenario, but a well-crafted log query can tie these breadcrumbs together.
There is a trade-off, though.
Log alerts typically have a longer latency than metric alerts – usually 5-15 minutes rather than near-immediate. They’re also more complex to set up. But when you need a digital detective looking for dodgy patterns, nothing else will do.
3) Activity log alerts for keeping tabs on admin changes
Who deleted that production database? When did that security rule change? Why is one of our connections down? Activity log alerts help answer these questions by notifying you about important administrative actions or service health issues.
These alerts are particularly valuable for:
- Security teams monitoring for unauthorised changes to critical resources
- Operations teams tracking successful and failed administrative actions
- Compliance officers ensuring policy adherence
- IT managers staying informed about Azure service issues
These alerts help you maintain control over who’s making changes to your environment and stay informed about Azure problems that might affect you.
4) Smart detection alerts that find problems for you
What if you don’t know exactly what to monitor for? Try smart detection alerts – the AI-powered members of your monitoring team that can spot patterns you might miss.
Using machine learning, these alerts establish baselines of normal behaviour and then ping you when something unusual happens. No thresholds to set, no queries to write – just automated anomaly detection.
You can see smart detection alerts catch subtle issues that would’ve gone unnoticed with traditional monitoring, like:
- A gradual memory leak that would eventually crash a service
- Unusual failure patterns affecting only a subset of users
- Dependency failures affecting one region but not others
- Abnormal spikes in exception rates following a deployment
Abilities like these pay off in complex, dynamic environments where setting static thresholds is impractical and where patterns might be too subtle for humans to notice immediately. It’s one of those areas where you’re probably okay with a machine taking over your job.
5) Cost and budget alerts to protect your wallet
Budget alerts are straightforward – they let you know when cloud spending approaches or exceeds your predefined budget thresholds. So, you can set alerts at 70%, 90%, and 100% of your monthly budget to avoid nasty surprises at month-end.
Cost anomaly alerts are a bit more sophisticated – they use AI to learn your normal spending patterns and alert you when something unusual happens. So, if your data transfer costs suddenly spike on a Tuesday afternoon when they’re usually low, you’ll know about it.
The upside of these alerts isn’t just that they protect your budget – they also create accountability and cost awareness across your organisation. When team members know their resource usage is being monitored, they can become more conscientious about cleaning up after themselves.